
A 150MB+ app binary file, like the one in Uber's app, takes between 500 ms and 1 second just to be loaded into memory (measured on an iPhone 6s). Loading large files like this is just a fraction of the app's launch time. To put in perspective, Apple's recommended startup time is just 400ms[1]. That's already 1-2x the recommended completed launch time without any code even executing!
By default, apps can need to read more than 75% of their binary during startup. However, with the help of order files, we can read only the functions we need during start up.
Pages
Why is so much of the binary used on startup? The answer lies in how iOS deals with memory. As new instructions are fetched from an app's binary file they must be loaded from disk into memory. Rather than loading one instruction or one byte at a time, the kernel loads one large chunk of memory, known as a page. On iOS a page is 16kb[2]. So the first time an instruction is needed from the app binary, the entire 16kb region surrounding that page is mapped into memory. This process is called a page fault.
Say the first 16kb of a binary contains code used by an obscure feature like captcha verification, but happens to include a single 100 byte function that's executed during app startup. Now the entire captcha feature needs to be loaded just to start the app. In practice, most or all of the binary will end up being loaded into memory during startup like this, as the startup functions are scattered around the binary.
Using order files
Order files rearrange binaries to allow reading just the code you need at startup.
Each function in source code is represented as an indivisible unit, commonly referred to as a symbol. The linker decides how these symbols are ordered and by default will group code defined in the same source file close together in the binary. However, when you provide the linker with an order file, this default behavior is overridden. The order file instructs the linker to put functions in a specific sequence. By ordering the binary so all the startup functions are together, we now only need to load those pages.
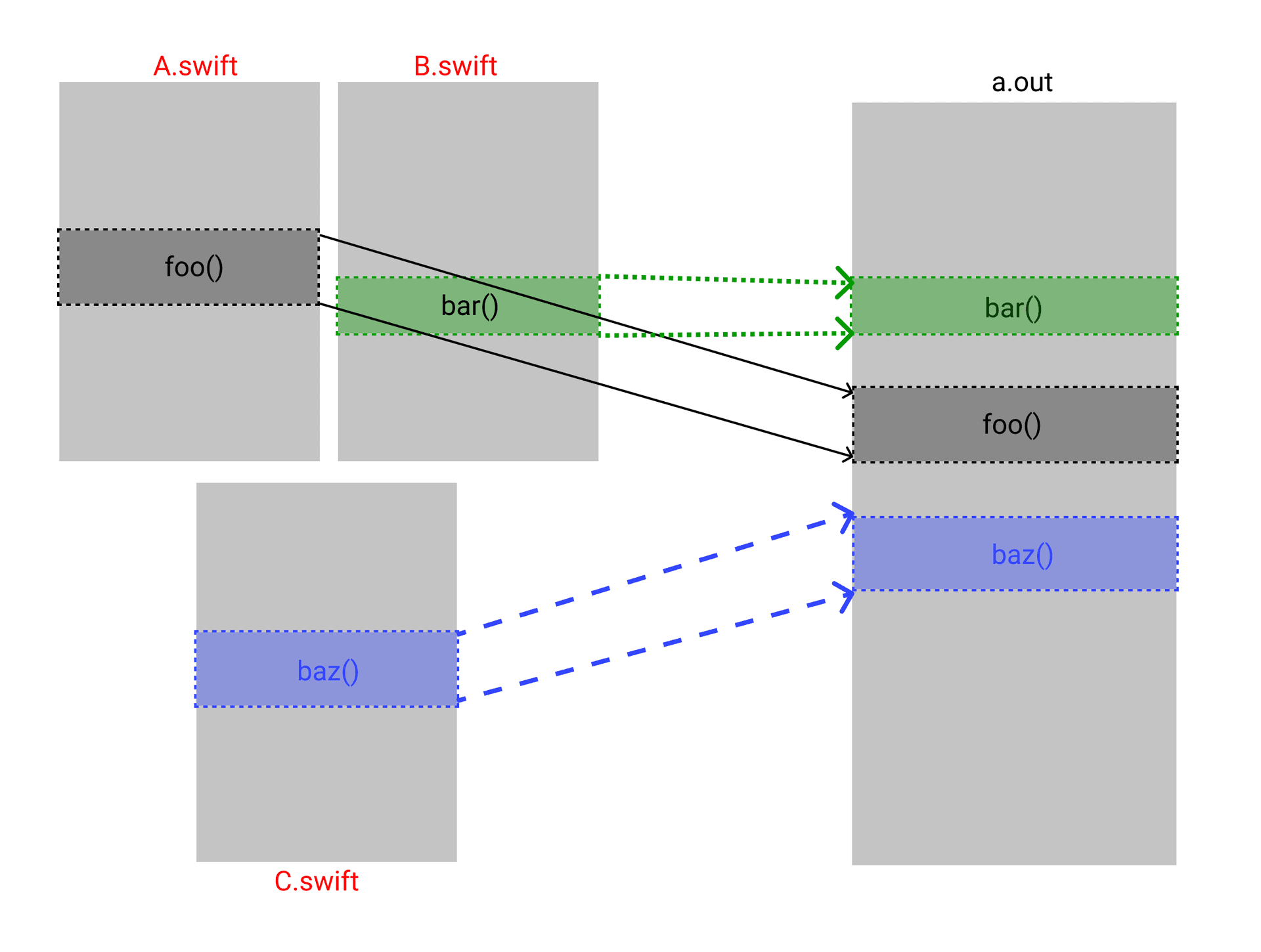
Page faults in theory
This is worth doing because a page fault is expensive. Like most computers, the iPhone has a memory hierarchy with an order of magnitude delay added between levels. A page fault reads data from the slowest level - the phone's flash storage (NAND).
Accessing memory that has already been brought into RAM is much faster, and memory residing in
the processor cache is the fastest. Each level gets smaller and smaller, that's why it's important to use as little memory as possible. The more memory used, the sooner low-latency caches fill up.
In practice there are even more sources of latency, for example validating code signatures.
Binaries are signed per-page, the first time a page is accessed the data must be hashed and compared to the signature. You can see this process in the kernel function vm_fault_validate_cs.
Page faults in practice
To measure page faults in practice, just dereference a pointer to each page in an app's binary.
I tested this with several apps on the store, and measured time to access each page in a linear scan. By plotting the time for each access you can see distinct bands representing each level of the cache hierarchy. The following experiments were on an iPhone 6S.
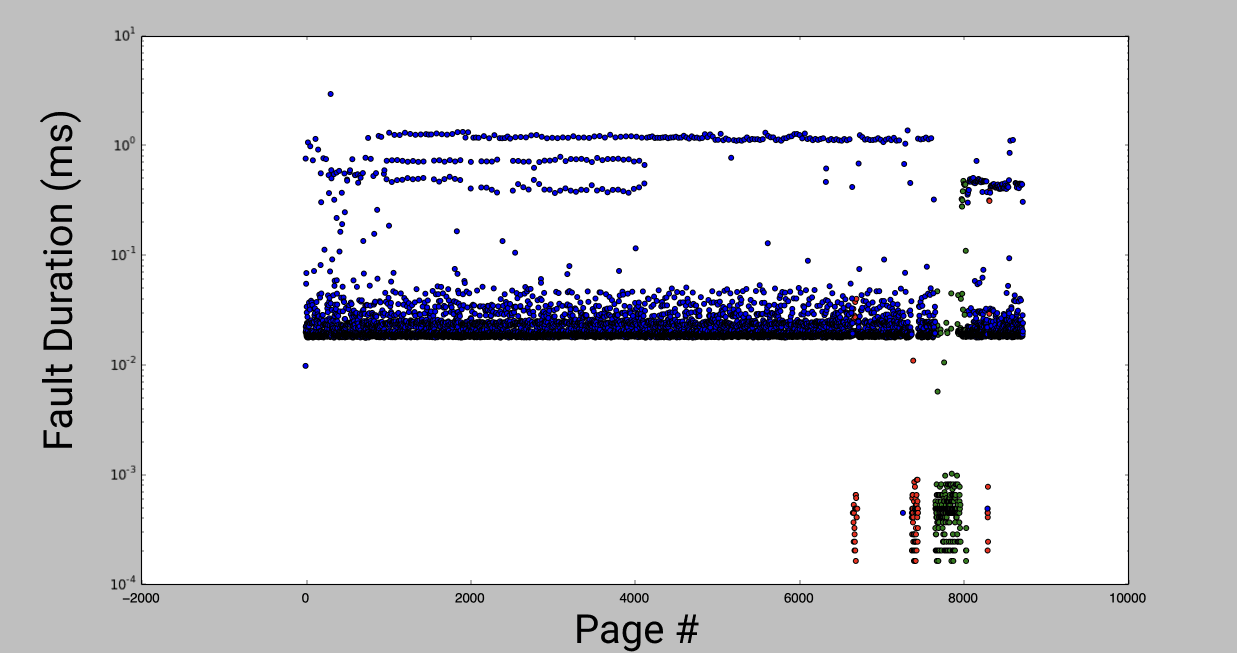
The outliers on the bottom right of the graph are pages that had extremely fast access times. These turn out to be in the Objective-C metadata and constant string[3] sections of the binary. Because the code measuring fault time is run after the Obj-C runtime is initialized, these pages were all already accessed. They were loaded in from flash storage even before the first line of code ran, and were already in a fast cache before I accessed them.
This distribution suggests that the worst case page fault takes about 1ms, but doesn't tell us much about the expected duration of a fault. To get that, I looked at cumulative time to read all pages of the binary.
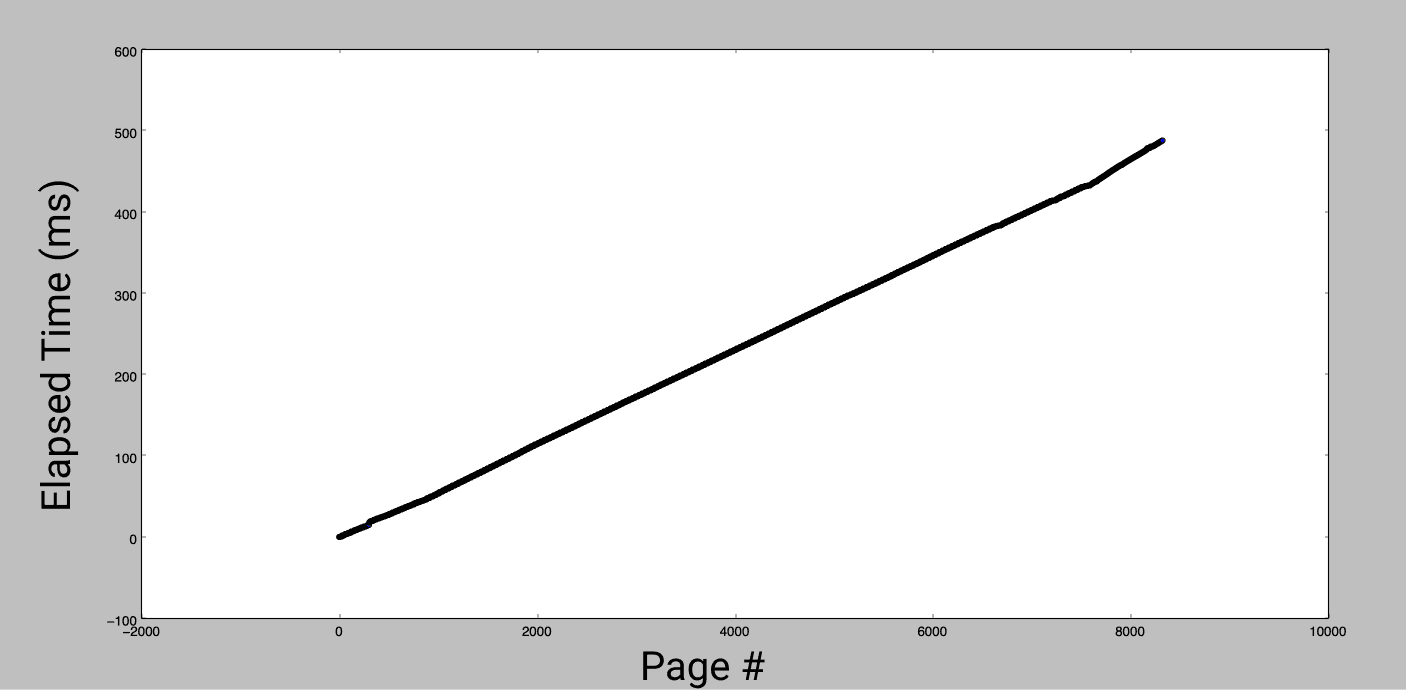
That's a clear trend! The average time for a fault is 0.06ms. However, it doesn't explain why we saw much fewer slow faults than fast faults. Let's zoom in on a small section of the graph:
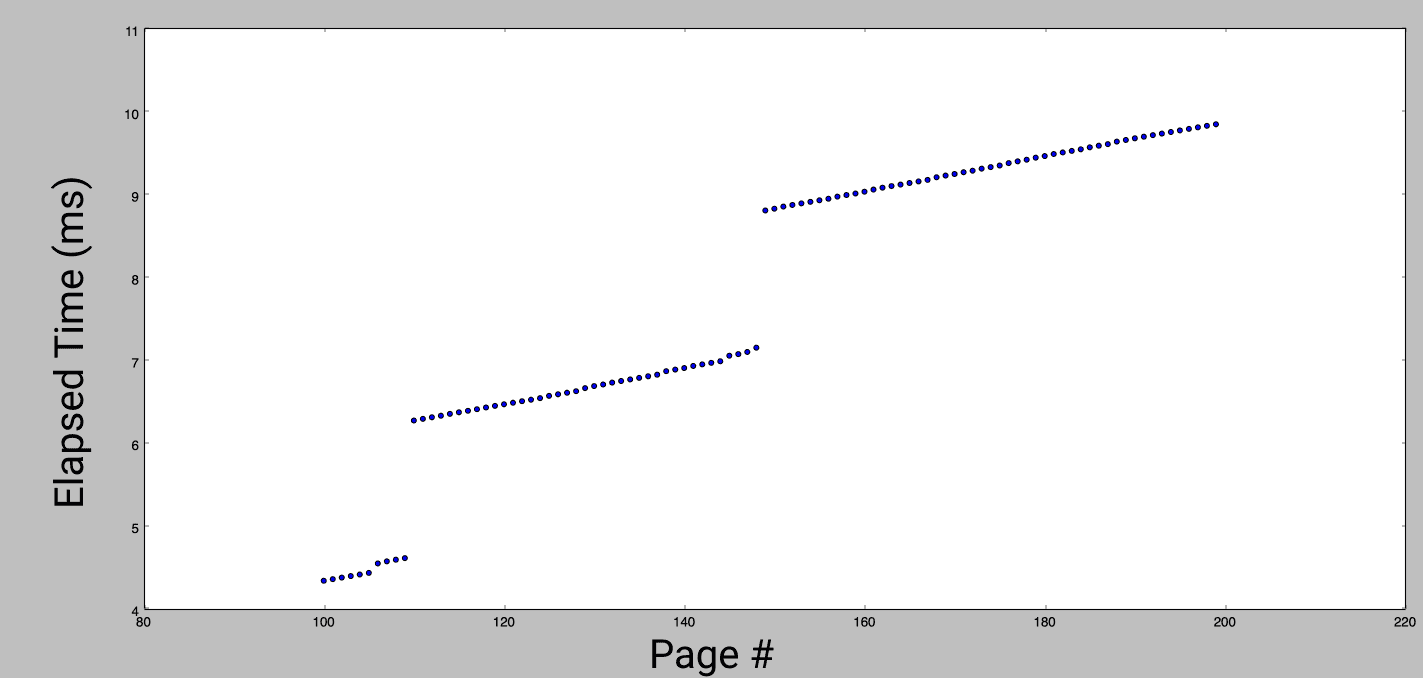
Most faults are fast, but every 40-50 faults there is a very slow access. It looks like a step function, and can be explained by system prefetching. Each new fault triggers an expensive lookup, which is actually bringing multiple pages into memory in anticipation of more pages being used. There is a performance cost to this, loading fewer pages would result in a faster worst-case [4], but this behavior makes a trade off favoring the amortized time. This trade-off is best exploited by in-order access. Out-of-order access can be even worse than not prefetching at all.
To see why, imagine a simplified case where 3 pages are prefetched.
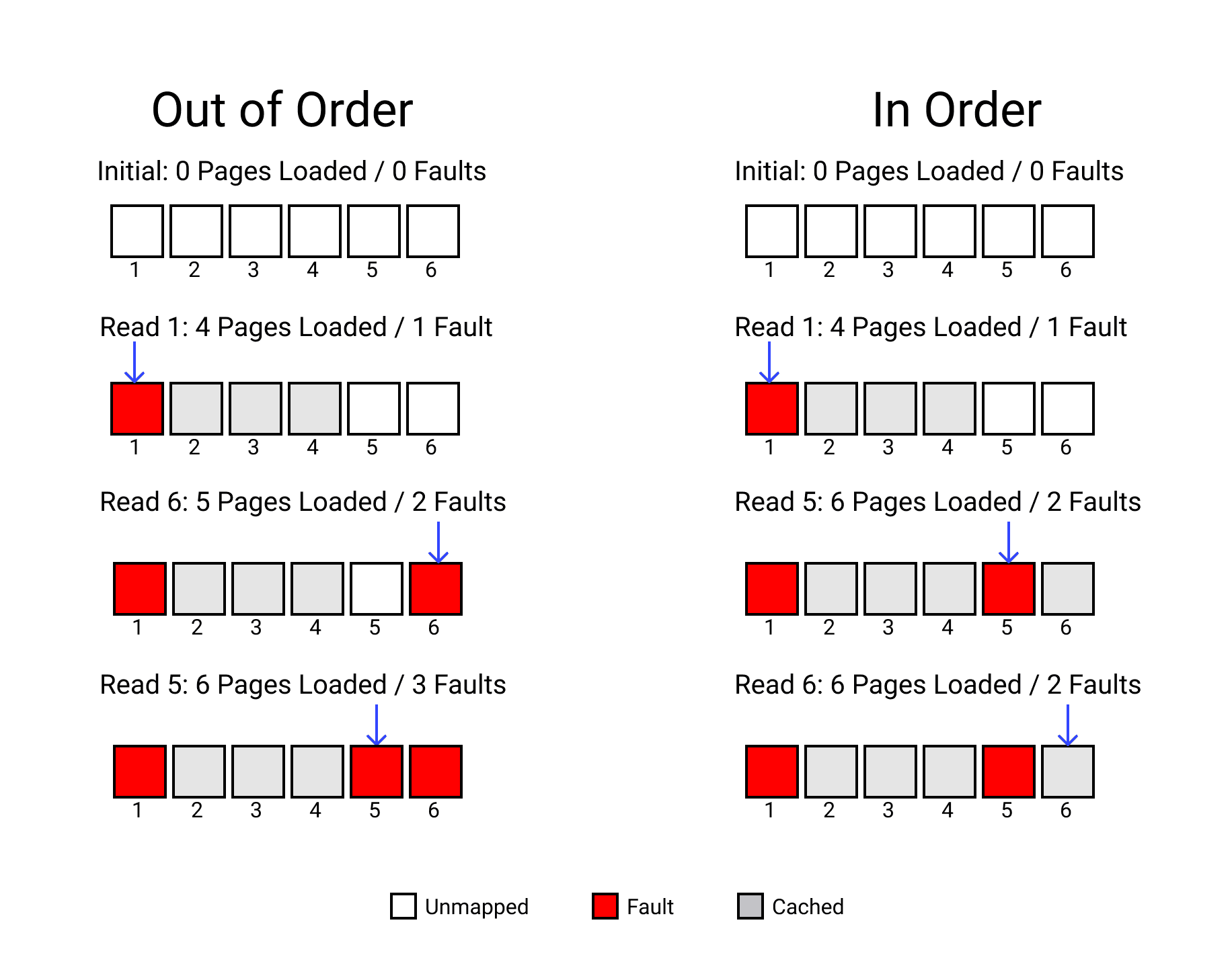
The out-of-order case needs 3 slow faults to read 3 pages, plus the time to cache 3 additional pages. The in-order case only takes 2 slow faults. If we changed which pages were used instead of just their order it could be only one slow fault.
Comparing orders
To measure this effect, I built a dylib that can be inserted into any app to detect the order of memory access. I ran it with large apps from the App Store, and reproduced their order of access in my measurement function. Combining this real-world page access pattern with the ideal in-order and a random access pattern shows us how much room for improvement there is.
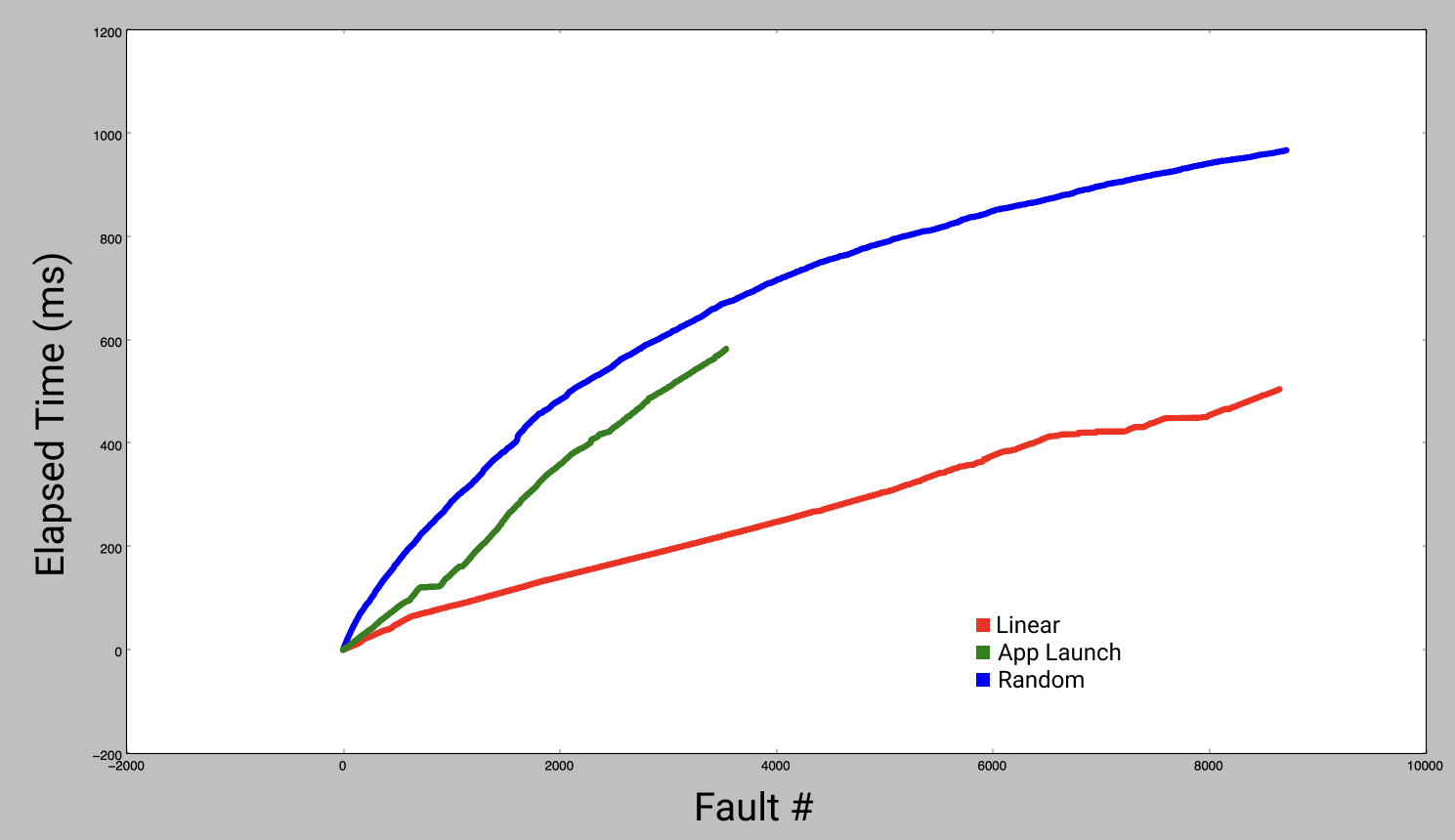
As expected, random order starts off much slower than linear order and the total time is significantly greater. The slope tapers off towards the end because so much of the app has already been prefetched. Reproducing the order of pages faulted during app launch was somewhere in between the best case and random access. Order files turn your app from the green line into the red line, while reducing the total number of pages.
Finally, to confirm that page access in a binary without an order file was relatively random, this graph shows the fault number (order of faults observed during app launch) vs. the page number (where the page is located within the binary).
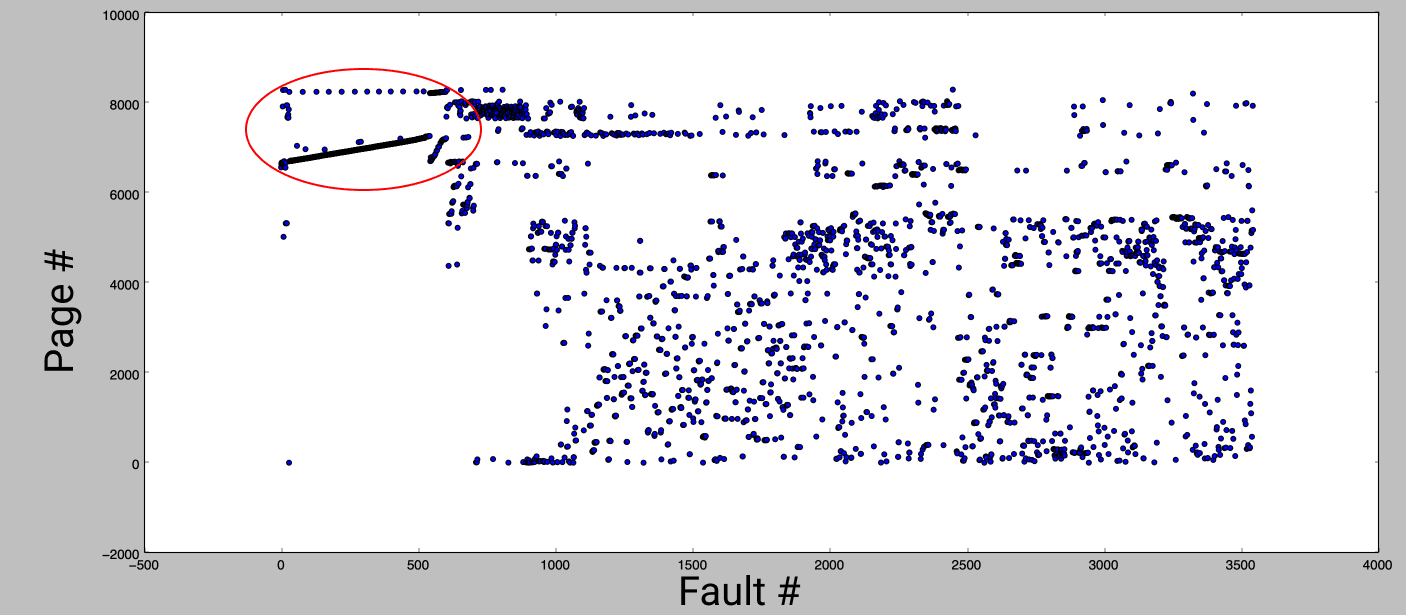
Most of the faults appear in a random order, except for a clear linear pattern at the very beginning of app launch (circled in red). All the pages on this line contain protocol conformance metadata. This behavior happens because of the linear scan of protocol conformances discussed in a previous blog post.
🚀️ Launch Booster
In summary, accessing a page of memory can vary from milliseconds to 1/100s of a millisecond depending on which caches have the page. Ordering symbols in an app binary lets the system optimize memory access to decrease the likelihood of a slow page fault and reduce the total number of page faults by placing the memory you need on as few pages as possible.
This research has led to Emerge's new Launch Booster, a binary ordering service that profiles apps in CI to determine the optimal ordering. Using Launch Booster, we've seen apps benefit from up to a 20% reduction in startup time!
Since the original publication, we've made even more Launch Booster improvements. You can read more about how we decreased protocol lookup times by 20% here.
If you're interested in Launch Booster or have any questions about order files, please let us know!
[1] WWDC 2019 - Session 423
[2] There are multiple systems that operate on pages and use different sizes. For example, code signing is done with 4kb pages. Page faults always involve a 16kb page, so we focus on that definition of page in this article.
[3] Including Objective-C class names, which are registered by the runtime before static initializers run.
[4] This can be seen by performing the same experiments on a smaller app binary. Fewer pages get prefetched, and each worst case is slightly faster.